Golang Map 入门到实现

文章目录
哈希表是一种巧妙并且实用的数据结构。它是一个无序的key/value对的集合,其中所有的key都是不同的,然后通过给定的key可以在常数时间复杂度内检索、更新或删除对应的value。
在Go语言中,一个map就是一个哈希表的引用,map类型可以写为map[K]V,其中K和V分别对应key和value。map中所有的key都有相同的类型,所有的value也有着相同的类型,但是key和value之间可以是不同的数据类型。其中K对应的key必须是支持==比较运算符的数据类型,所以map可以通过测试key是否相等来判断是否已经存在。虽然浮点数类型也是支持相等运算符比较的,但是将浮点数用做key类型则是一个坏的想法.
Map 的基本操作
创建一个 Map
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
type User struct{
id int
age int
}
// 短声明 + make
userMap := make(map[string]User, cap)
// 短声明 + 初始化
userMap := map[string]{
Bob: User{
id, 1
age, 21
},
Lee: User{
id, 2
age, 22
}
} |
增删改查
通过 key 查找对应 value > user : = userMap["Bob"] // user{id: 1, age: 22}
遍历所有 key/value
1 2 3 |
for name, user := range userMap {
fmt.Printf("%s\t%s\n", name, user)
} |
map 的顺序性
1 2 3 4 5 6 7 8 9 10 |
import "sort"
var names []string
for name := range ages {
names = append(names, name)
}
sort.Strings(names) // 显示排序
for _, name := range names {
fmt.Printf("%s\t%d\n", name, ages[name])
} |
内置的 delete 函数删除元素 > delete(usermMap, "Bob")
所有这些操作是安全的,即使这些元素不在map中也没有关系;如果一个查找失败将返回value类型对应的零值,例如,即使map中不存在“bob”下面的代码也可以正常工作,因为 userMap["bob"]失败时将返回 nil。
修改 (赋值)
> userMap["Bob"] = User{
id: 1,
age: 22,
}
利用 Map 实现一个 Set 集合
Go语言中并没有提供一个 set 类型,但是 map 中的 key 也是不相同的,可以用 map 实现类似 set 的功能 > userSet := map[User]bool
容器和结构体(map and struct)
语法比较: map[type]struct map[type]*struct
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
package main import "fmt" func main() { type user struct{ name string } /* 当 map 因扩张而重新哈希时,各键值项存储位置都会发生改变。 因此,map 被设计成 not addressable。 类似 m[1].name 这种期望透过原 value 指针修改成员的行为自然会被禁 。 */ m := map[int]user{ // 1: {"user1"}, } // m[1].name = "Tom" // ./main.go:16:12: cannot assign to struct field m[1].name in map fmt.Println(m) // 正确做法是完整替换 value 或使用指针。 u := m[1] u.name = "Tom" m[1] = u // 替换 value。 m2 := map[int]*user{ 1: &user{"user1"}, } m2[1].name = "Jack" // 返回的是指针复制品。透过指针修改原对象是允许的。 fmt.Println(m2) 结果: map[1:{user1}] map[1:0xc42000e1e0] } |
Map 的实现(源码解析)
map基本数据结构
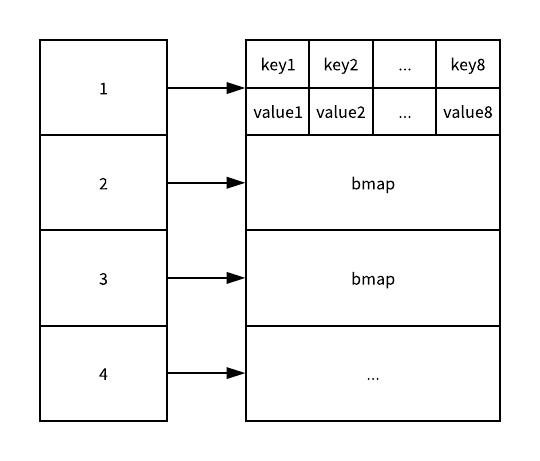
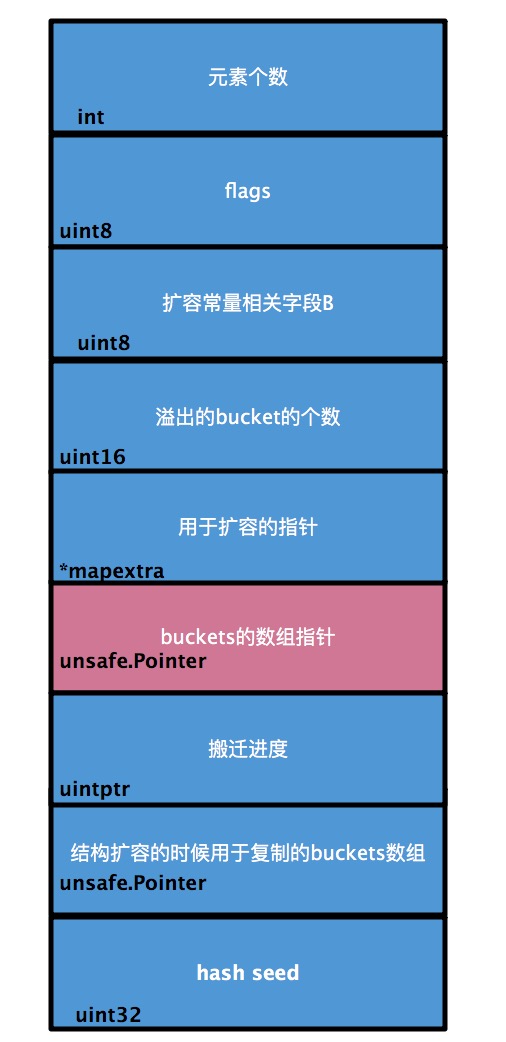
map的底层结构是hmap(即hashmap的缩写),核心元素是一个由若干个桶(bucket,结构为bmap)组成的数组,每个bucket可以存放若干元素(通常是8个),key通过哈希算法被归入不同的bucket中。当超过8个元素需要存入某个bucket时,hmap会使用extra中的overflow来拓展该bucket。下面是hmap的结构体。
1 2 3 4 5 6 7 8 9 10 11 12 13 |
type hmap struct {
count int // # 元素个数
flags uint8
B uint8 // 说明包含2^B个bucket
noverflow uint16 // 溢出的bucket的个数
hash0 uint32 // hash种子
buckets unsafe.Pointer // buckets的数组指针
oldbuckets unsafe.Pointer // 结构扩容的时候用于复制的buckets数组
nevacuate uintptr // 搬迁进度(已经搬迁的buckets数量)
extra *mapextra
} |
bmap 桶结构 > 哈希表的类型其实都存储在每一个桶中,这个桶的结构体 bmap 其实在 Go 语言源代码中的定义只包含一个简单的 tophash 字段:
1 2 3 4 |
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
} |
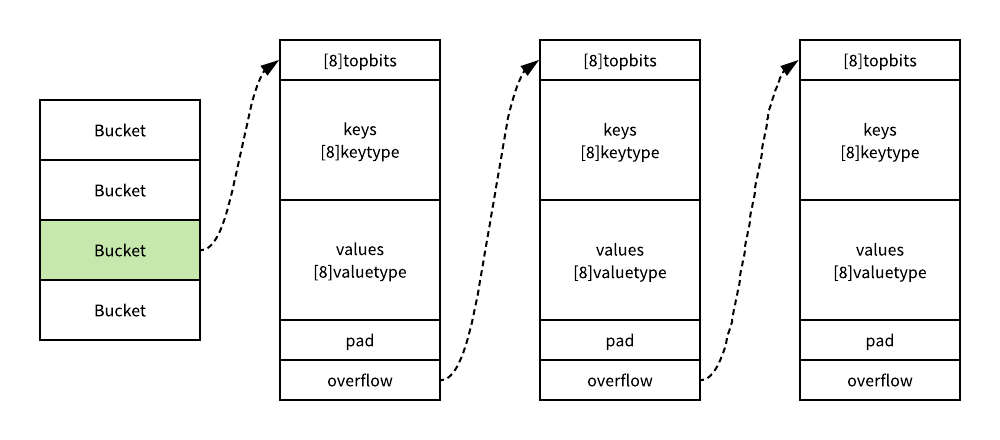
哈希表中桶的真正结构其实是在编译期间运行的函数 bmap 中被『动态』创建的: > 这种做法是因为 Go 语言在执行哈希的操作时会直接操作内存空间,与此同时由于键值类型的不同占用的空间大小也不同,也就导致了类型和占用的内存不确定,所以没有办法在 Go 语言的源代码中进行声明。重建之后
1 2 3 4 5 6 7 |
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
} |
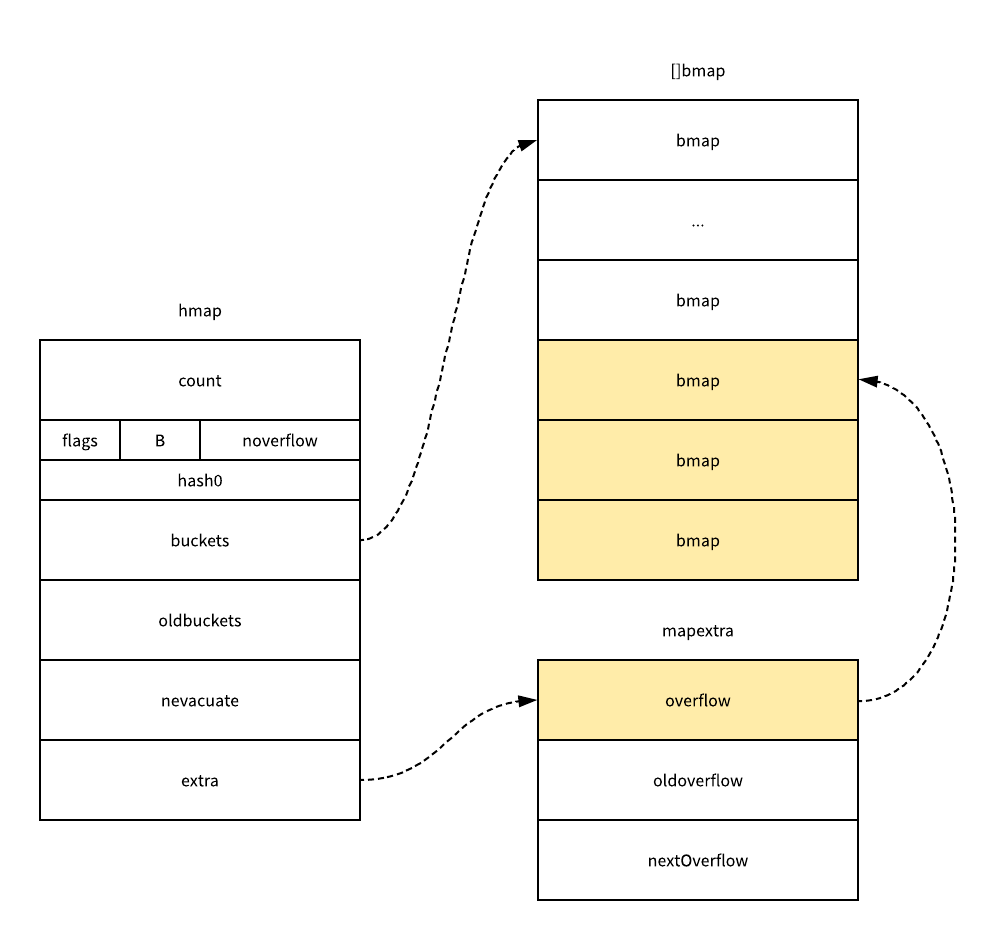
 每一个哈希表中的桶最多只能存储 8 个元素,如果桶中存储的元素超过 8 个,那么这个哈希表的执行效率一定会急剧下降,不过在实际使用中如果一个哈希表存储的数据逐渐增多,我们会对哈希表进行扩容或者使用额外的桶存储溢出的数据,不会让单个桶中的数据超过 8 个:
> 溢出桶只是临时的解决方案,创建过多的溢出桶最终也会导致哈希的扩容。
每一个哈希表中的桶最多只能存储 8 个元素,如果桶中存储的元素超过 8 个,那么这个哈希表的执行效率一定会急剧下降,不过在实际使用中如果一个哈希表存储的数据逐渐增多,我们会对哈希表进行扩容或者使用额外的桶存储溢出的数据,不会让单个桶中的数据超过 8 个:
> 溢出桶只是临时的解决方案,创建过多的溢出桶最终也会导致哈希的扩容。
 map doc go 1.12 runtime/map.go
map doc go 1.12 runtime/map.go
1 2 3 4 5 6 7 8 9 10 11 12 |
// This file contains the implementation of Go's map type. // // A map is just a hash table. The data is arranged // into an array of buckets. Each bucket contains up to // 8 key/value pairs. The low-order bits of the hash are // used to select a bucket. Each bucket contains a few // high-order bits of each hash to distinguish the entries // within a single bucket. // // If more than 8 keys hash to a bucket, we chain on // extra buckets. // |
访问
在编译的 类型检查 阶段,所有的类似 hash[key] 的 OINDEX 操作都会被转换成 OINDEXMAP 操作,然后在 中间代码生成 之前会在 walkexpr 中将这些 OINDEXMAP 操作转换成如下的代码
1 2 |
v := hash[key] // => v := *mapaccess1(maptype, hash, &key) v, ok := hash[key] // => v, ok := mapaccess2(maptype, hash, &key) |
写入
当形如 hash[k] 的表达式出现在赋值符号左侧时,与读取时一样会在编译的 类型检查 和 中间代码生成 期间被转换成调用 mapassign 函数调用,我们可以将该函数分成几个部分介绍,首先是函数会根据传入的键拿到对应的哈希和桶:
当前的哈希表没有处于扩容状态并且装载因子已经超过了 6.5 或者存在了太多溢出的桶时,就会调用 hashGrow 对当前的哈希表进行扩容。
> 装载因子是同时由 loadFactorNum 和 loadFactDen 两个参数决定的,前者在 Go 源代码中的定义是 13 后者是 2,所以装载因子就是 6.5。
如果当前的桶已经满了,就会调用 newoverflow 创建一个新的桶或者使用 hmap 预先在 noverflow 中创建好的桶来保存数据,新创建桶的指针会被追加到已有桶中,与此同时,溢出桶的创建会增加哈希表的 noverflow 计数器。