Redis字典的实现 《Redis设计与实现》

文章目录
Redis字典的实现 《Redis设计与实现》
实现字典的方法有很多种:
1 2 3 |
1. 最简单的就是使用链表或数组,但是这种方式只适用于元素个数不多的情况下 2. 要兼顾高效和简单性,可以使用哈希表; // Hash无法实现稳定性 3. 如果追求更为稳定的性能特征,并且希望高效地实现排序操作的话,则可以使用更为复杂的平衡树 |
在众多可能的实现中,Redis 选择了高效且实现简单的哈希表作为字典的底层实现
字典的数据结构
源文件 dict.h/dict 给出了字典的定义
1 2 3 4 5 6 7 8 9 10 11 12 13 |
/ ** 字典 ** 每个字典使用两个哈希表,用于实现渐进式 rehash */
typedef struct dict {
// 特定于类型的处理函数
dictType *type;
// 类型处理函数的私有数据
void *privdata;
// 哈希表(2 个)
dictht ht[2];
// 记录 rehash 进度的标志,值为-1 表示 rehash 未进行
int rehashidx;
// 当前正在运作的安全迭代器数量
int iterators;
} dict; |
以下是用于处理 dict 类型的 API ,它们的作用及相应的算法复杂度:
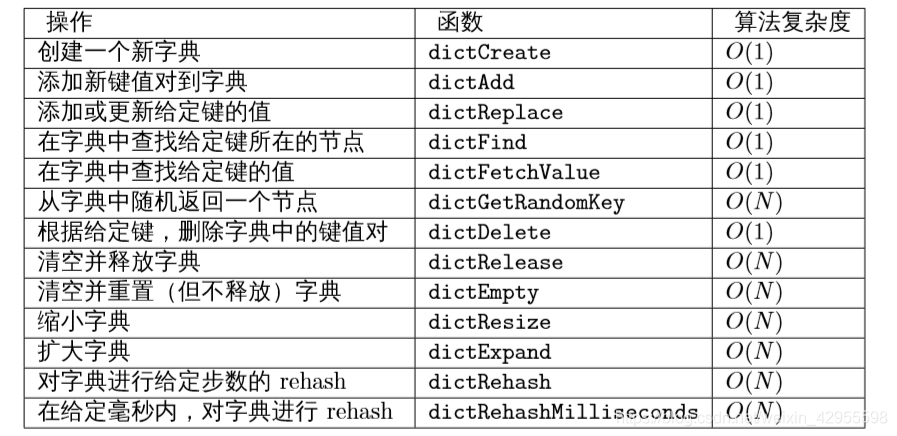 注意 dict 类型使用了两个指针分别指向两个哈希表。
其中,0 号哈希表(ht[0])是字典主要使用的哈希表,而 1 号哈希表(ht[1])则只有在程序 对 0 号哈希表进行 rehash 时才使用。
接下来两个小节将对哈希表的实现,以及哈希表所使用的哈希算法进行介绍。
注意 dict 类型使用了两个指针分别指向两个哈希表。
其中,0 号哈希表(ht[0])是字典主要使用的哈希表,而 1 号哈希表(ht[1])则只有在程序 对 0 号哈希表进行 rehash 时才使用。
接下来两个小节将对哈希表的实现,以及哈希表所使用的哈希算法进行介绍。
哈希表实现
哈希表实现由 dict.h/dictht 类型定义
1 2 3 4 5 6 7 8 9 10 11 |
/* * 哈希表 */
typedef struct dictht {
// 哈希表节点指针数组(俗称桶,bucket)
dictEntry **table;
// 指针数组的大小
unsigned long size;
// 指针数组的长度掩码,用于计算索引值
unsigned long sizemask;
// 哈希表现有的节点数量
unsigned long used;
} dictht; |
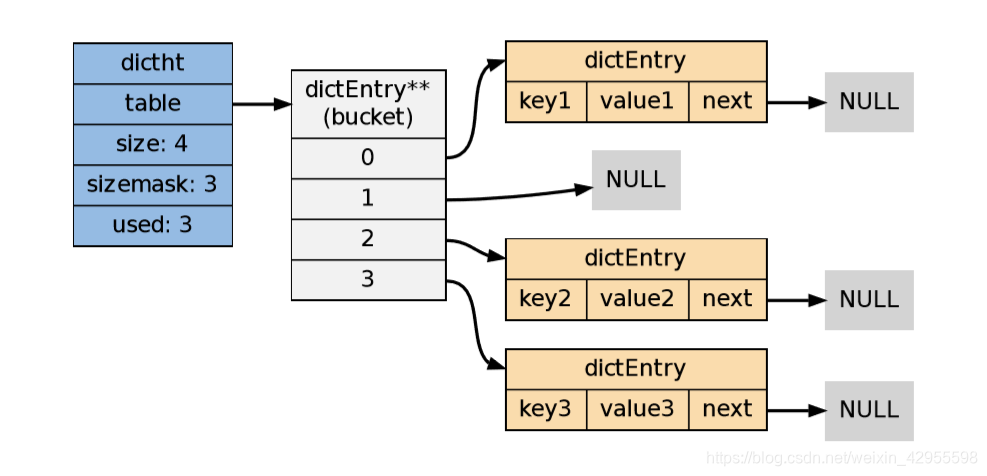
table 属性是一个数组,数组的每个元素都是一个指向 dictEntry 结构的指针。 每个 dictEntry 都保存着一个键值对,以及一个指向另一个 dictEntry 结构的指针:
1 2 3 4 5 6 7 8 9 |
/* * 哈希表节点 */
typedef struct dictEntry {
// 键
void *key;
// 值
union { void *val; uint64_t u64; int64_t s64; } v;
// 链往后继节点
struct dictEntry *next;
} dictEntry; |
next 属性指向另一个 dictEntry 结构,多个 dictEntry 可以通过 next 指针串连成链表,从 这里可以看出,dictht 使用链地址法来处理键碰撞:当多个不同的键拥有相同的哈希值时,哈 希表用一个链表将这些键连接起来。
下图展示了一个由 dictht 和数个 dictEntry 组成的哈希表例子:
 如果再加上之前列出的 dict 类型,那么整个字典结构可以表示如下:
如果再加上之前列出的 dict 类型,那么整个字典结构可以表示如下:
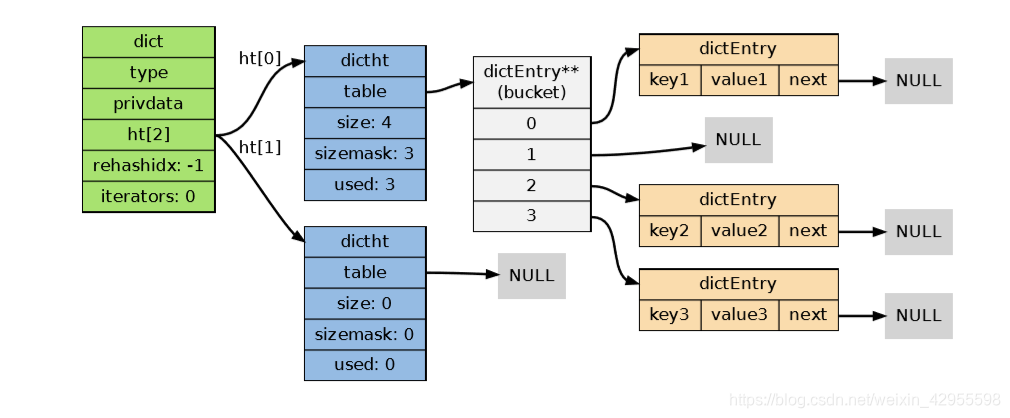 在上图的字典示例中,字典虽然创建了两个哈希表,但正在使用的只有 0 号哈希表,这说明字 典未进行 rehash 状态。
在上图的字典示例中,字典虽然创建了两个哈希表,但正在使用的只有 0 号哈希表,这说明字 典未进行 rehash 状态。
内容来自: 《Redis设计与实现》